CS336
这是25年春CS336的课堂笔记和作业,课程网站为Stanford CS336 | Language Modeling from Scratch,课程视频可在哔哩哔哩上观看:斯坦福CS336:大模型从0到1。
此课程内容涵盖分词、模型架构、系统优化、数据处理和模型对齐等方面,通过从零开始构建语言模型,深入理解NLP和AI的核心技术。
Tokenization
什么是分词(Tokenization)
分词是将**字符串(文本)转换为令牌(tokens,通常是整数索引)**的过程,以便语言模型处理。反过来,也需要将令牌解码回字符串。分词器(Tokenizer)需要实现以下两个方法:
- encode:将字符串编码为整数序列(tokens)。
- decode:将整数序列解码回字符串。
1 | string = "Hello, 🌍! 你好!" |
分词评估指标
-
词汇表大小(Vocabulary Size)
指分词器能够生成的所有可能 token 的数量,通常表示为整数索引的范围。
-
压缩率(Compression Ratio)
压缩率衡量每个 token 平均代表的字节数,计算公式为:
其中num_bytes表示输入字符串的 UTF-8 编码字节数;num_tokens表示分词后生成的 token 数量。
-
序列长度(Sequence Length)
分词后生成的 token 序列的长度,即
len(indices)。它直接影响语言模型的计算成本和性能。
分词策略
基于字符的分词(Character-based Tokenization)
顾名思义就是将每个 Unicode 字符转换为对应的代码点(整数),例如:
1 | "Hello, 🌍!" → [72, 101, 108, 108, 111, 44, 32, 127757, 33] |
这种分词方法简单直接,适用于任何 Unicode 文本;同时解码和编码过程明确且可逆。
但是:
- 词汇表过大:Unicode 字符约有 150,000 个,导致词汇表巨大,模型学习效率低。
- 稀有字符问题:如 🌍 等字符使用频率低,浪费词汇表空间。
- 压缩率低:每个字符一个 token,序列长度长,影响模型效率(尤其是 Transformer 的上下文长度受限)。
基于字节的分词(Byte-based Tokenization)
将字符串编码为 UTF-8 字节序列,每个字节是一个整数(0-255)。例如:
1 | assert bytes("a", encoding="utf-8") == b"a" |
这种分词方式显然词汇表很小,毕竟只有256种可能。但是压缩率差,因为一个字符可能对应多个byte,压缩率几乎为1,导致 token 序列过长(注意力机制的二次方复杂度,token过长效率下降)。
UTF-8、ASCII 和 Unicode字符编码
- ASCII码:被设计用于仅英文字符的编码标准,包括大小写英文字母、10个数字、标点与空格/制表符这种控制字符。通常使用8位二进制来表示字符,例如字母 ‘A’ 的 ASCII 码是 65(二进制:01000001)。
- Unicode:旨在为世界上几乎所有语言的字符分配一个唯一的编码(码点),目前定义了超过 14 万个字符,涵盖多种语言、符号、表情等。码点通常表示为
U+XXXX,例如汉字“中”的 Unicode 码点是U+4E2D。这种方法解决了 ASCII 的局限性,支持多语言文本。- UTF-8:其中一种将 Unicode 码点编码为字节序列的变长编码方案,用于在计算机中存储或传输 Unicode 字符。其可以兼容ASCII码(ASCII 字符0-127在 UTF-8 中直接用 1 字节表示,与 ASCII 编码相同);此外还根据字符的 Unicode 码点进行变长编码,比如中文用3 byte,表情符号用4 byte。
基于单词的分词(Word-based Tokenization)
使用正则表达式(如 \w+|.)将文本分割为单词或标点。例如:
1 | "I'll say supercalifragilisticexpialidocious!" → ["I'll", "say", "supercalifragilisticexpialidocious", "!"] |
这种分词更符合人类语言的语义单位(单词),压缩率也能比较高,它面临的问题就是:
- 词汇表过大:单词数量可能非常多(尤其是罕见单词)。
- 稀有单词问题:新词或未见过的词需要用特殊 token(如
<UNK>)表示,影响模型性能。 - 词汇表大小不固定:依赖训练数据,难以控制。
字节对编码(Byte Pair Encoding, BPE)
字节对编码(Byte Pair Encoding, BPE)是一种数据压缩算法,最初用于压缩文本,后来被适配到NLP中,BPE 的核心思想是:
- 从字节级别开始,将最常见的**相邻字节对(byte pairs)**合并为新的 token,逐步构建一个词汇表。
- 通过合并规则,将常见的字符序列表示为单个 token,减少 token 序列长度,提高压缩率,同时保持适中的词汇表大小。
BPE 的核心是通过统计语料中的字节对频率,迭代合并最常见的字节对,生成新的 token。它分为两个阶段:
- 训练阶段:根据语料统计字节对频率,生成词汇表(vocab)和合并规则(merges)。
- 编码/解码阶段:使用训练好的词汇表和合并规则,将输入字符串编码为 token 序列,或将 token 序列解码回字符串。
训练过程是这样的:假设输入为the cat in the hat
-
Step 1:把文字拆成最小的字节
将输入的文字转成 UTF-8 字节(每个字节是个 0-255 的数字),例如
the cat in the hat被转换为:1
[116, 104, 101, 32, 99, 97, 116, 32, 105, 110, 32, 116, 104, 101, 32, 104, 97, 116]
-
Step 2:找最常见的组合
BPE 会数一数,哪些两个字节老是挨着出现。比如,“t”和“h”(116, 104)出现了两次(“the”和“the”里各一次)。因此它决定把“t”和“h”粘在一起,变成一个新块,编号是 256(因为 0-255 已经被字节用完了),然后把所有“t h”替换成 256。现在句子变成:
1
2# 256 表示“th”
[256, 101, 32, 99, 97, 116, 32, 105, 110, 32, 256, 101, 32, 104, 97, 116] -
Step 3:再找下一个常见组合
现在发现“th”和“e”(256, 101)出现了两次,把“th”和“e”粘成一个新块,编号 257(表示“the”)。替换后,句子变成:
1
2# 257 表示“the”
[257, 32, 99, 97, 116, 32, 105, 110, 32, 257, 32, 104, 97, 116] -
Step 4:还在GO
再找常见组合,比如“a”和“t”(97, 116)出现两次(“cat”和“hat”里),粘成新块,编号 258(表示“at”)。替换后,句子变成:
1
2# 258 表示“at”
[257, 32, 99, 258, 32, 105, 110, 32, 257, 32, 104, 258] -
Step 5:STOP条件
可以设定一个次数(比如合并 3 次),或者直到词汇表大小合适(比如 500 个块)就停下来。
最终得到:
- 词汇表:记录每个编号对应的块,比如
{116: b't', 104: b'h', 256: b'th', 257: b'the', 258: b'at'}。 - 合并规则:记录哪些块粘在一起,比如
{(116, 104): 256, (256, 101): 257, (97, 116): 258}。
- 词汇表:记录每个编号对应的块,比如
对于编码,假设输入为the quick brown fox,按步骤操作:
-
先转成字节
1
[116, 104, 101, 32, 113, 117, 105, 99, 107, 32, 98, 114, 111, 119, 110, 32, 102, 111, 120]
-
按合并规则替换:
- “t h” → 256(th):[256, 101, 32, 113, 117, 105, 99, 107, …]
- “th e” → 257(the):[257, 32, 113, 117, 105, 99, 107, …]
- 没有“a t”组合,停止。
-
最终
1
[257, 32, 113, 117, 105, 99, 107, 32, 98, 114, 111, 119, 110, 32, 102, 111, 120]
BPE能够实现:
- 动态词汇表:通过训练自动生成词汇表,适应不同语料(如英语、中文、代码等);可以通过
num_merges控制词汇表大小。 - 高压缩率:常见序列被合并为单一 token,减少序列长度。
- 未见字符或词可以通过字节级别表示,不会产生
<UNK>token。
Assignment 1 (Part 2)
CS336_spring2025/assignment1-basics/cs336_basics/Part2
Pytorch基本构件与资源管理
内存管理
**张量(tensors)**是深度学习的基本构建块,用于存储参数、梯度、优化器状态和数据。张量的创建方式多种多样:
1 | x = torch.tensor([[1, 2, 3], [4, 5, 6]]) # @inspect x |
张量拥有不同数据类型(float32、float16、bfloat16、FP8),不同数据类型也决定了这个张量占多少空间。
-
float32(fp32、单精度)

作为创建张量时的默认数据类型。一个fp32变量占用32bit空间,即4字节。
此外还有float64(fp64,双精度),但在深度学习中并不常用
-
float16(fp16,半精度)
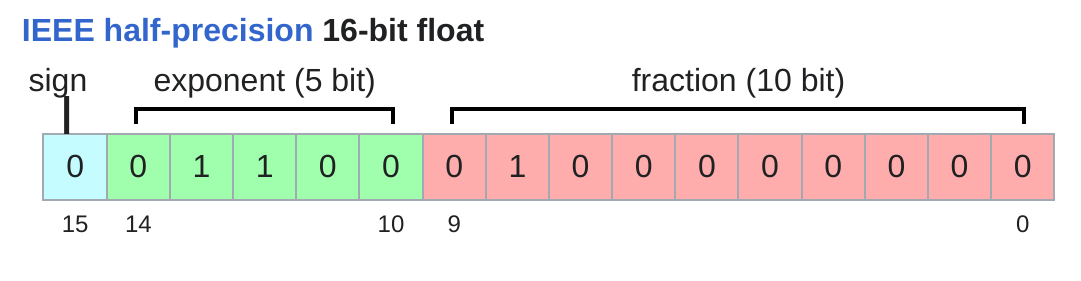
内存占用相比fp32减半。fp16相比fp32就不适合表示特别大或者特别小的数(上溢或下溢)。
-
bfloat16
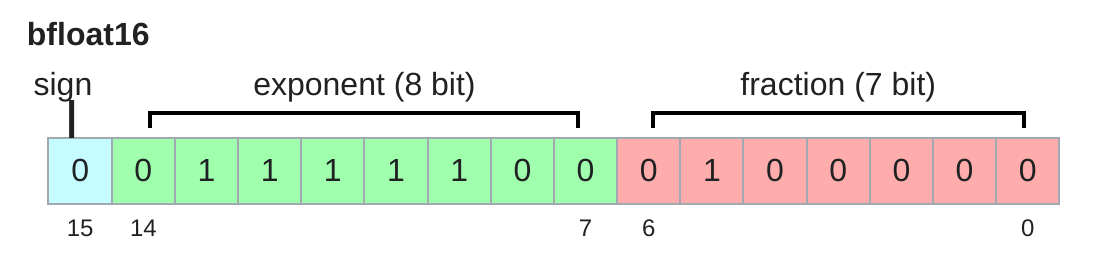
float16的进化版,在fp16的基础上扩大了数的表示范围,减小了数值的表示精度(但这个对深度学习来说影响不大)。
-
fp8

更加粗略的数据类型,包括E4M3和E5M2两种,分别对应不同的范围和精度。
在日常的训练过程中,我们常会在模型不同层、不同存储内容中采用不同的数据类型,即混合精度训练(mixed precision training)。
计算管理
张量在默认情况下保存在CPU内存中,可以通过下面的指令将张量转移至GPU内存中:
1 | x = torch.zeros(32, 32) |
Pytorch中的张量实际上以数组的形式存储,如果知道该元素在张量中的坐标,就能知道其在数组中的位置。
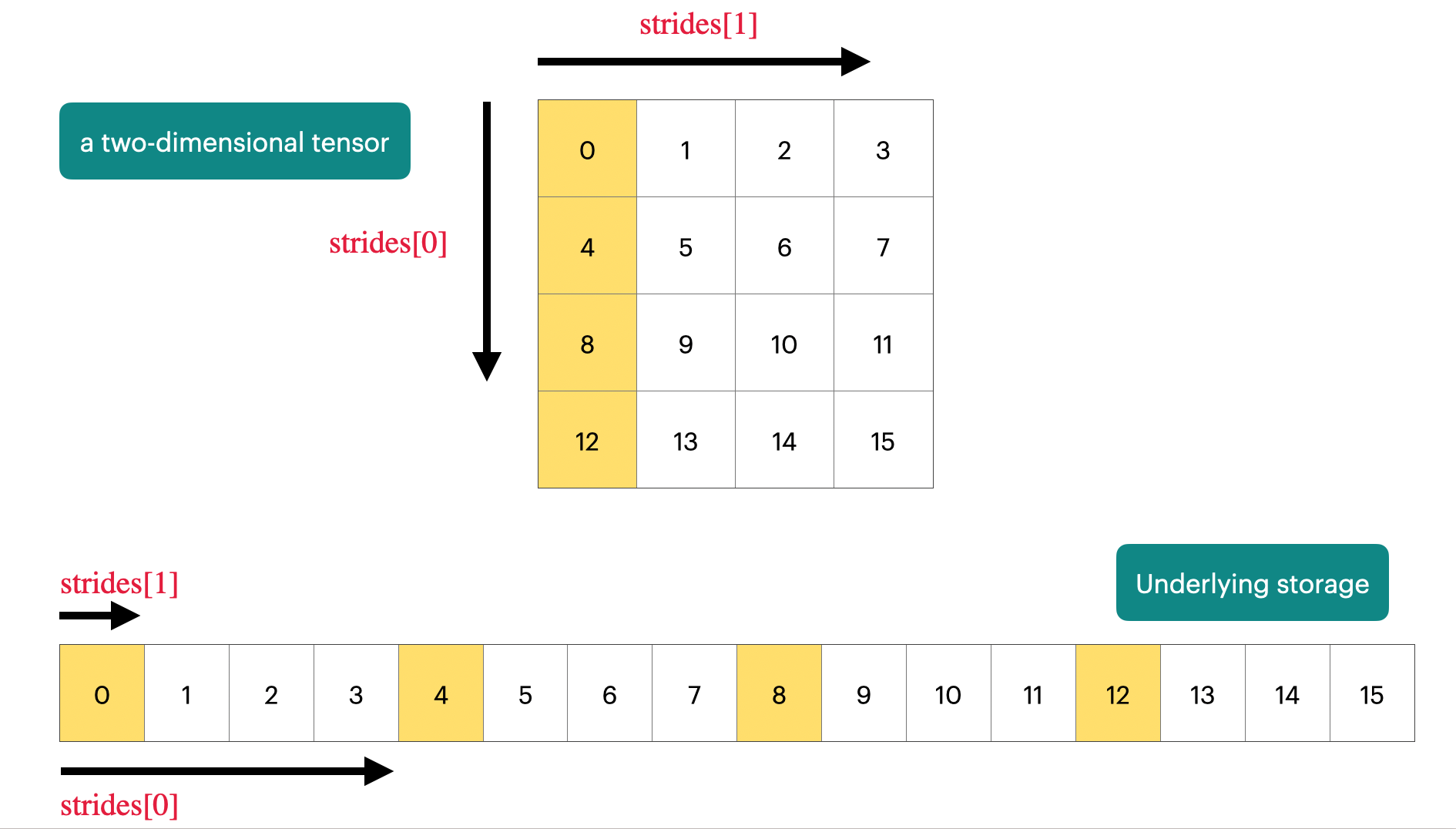
在矩阵乘法中,张量的用法是这样的:
1 | x = torch.ones(16, 32) |
LLM基本架构
最原汁原味的transformer架构可见机器学习与深度学习基础 | 好急好急的Hexo博客,本节讨论的内容主要是transformer中的各个组件的变体及当前最新的改进版transformer。




