系统软件安全
这门课从操作系统安全机制到网络安全这几节属于系统安全;从安全编程往后为软件安全(虽然后面开始接着编译原理了,还夹杂着一些软件分析的内容)
课上画的重点
- 概述这一章以了解为主即可
- 操作系统安全机制:安全威胁的表现形式(病毒、木马这种)、各种分类、常用安全机制、设计与实现
- Windows系统:用户模式和内核模式、安全组件的每个步骤(每个是干什么用的)。访问控制这块
- Linux系统:密码保存、procfs、文件属性、文件访问流程
- 移动系统:系统对比、宏内核微内核
- 网络安全:不同协议安全、防火墙、入侵检测
- 安全编程:理解即可
- 语义分析:综合属性和继承属性、SL属性形式、语法制导翻译方案、递归下降和LL语法分析
- 中间代码生成:三地址码、类型检查(综合与推导)、类型推导、控制流
- 代码生成:基本块、流图、窥孔优化
- 课设相关
- 指针分析里面那个anderson算法
- 防火墙,访问控制,入侵检测系统的分类,还有系统安全那部分那种对比的表格里面的东西
概述
系统安全与软件安全概述
- 系统安全:系统是由多个组件相互协作形成的整体,安全是其稳定运行的基础。安全目标是确保系统的机密性、完整性和可用性,防止未经授权的访问和破坏。
- 软件安全:保护软件免受恶意攻击、未经授权访问和数据泄露等威胁。核心要素包括机密性、完整性和可用性,确保软件正常运行且信息不被篡改或泄露。
威胁与风险
威胁指可能破坏系统或软件安全性的潜在因素,风险则是威胁发生的可能性及其造成的后果。
通过风险评估和威胁建模来识别潜在威胁与风险,并采取相应的安全策略和控制措施以降低风险。
漏洞与补丁
- 漏洞:指系统或软件中可被利用的弱点或缺陷
- 补丁:修复系统或软件中已知漏洞的程序更新或修正
加密与解密
- 加密技术:采用特定算法将明文转换为密文,确保数据在传输或存储过程中不被未授权访问
- 解密技术:将密文还原为原始明文的过程,确保合法用户能够正常访问数据内容
系统软件安全事件
事件发生的原因有:
- 技术漏洞:系统或软件中的技术缺陷导致安全漏洞,成为攻击者的突破口。
- 人为失误:操作不当或管理疏忽引发安全事件,如弱密码、未及时更新等。
- 外部攻击:黑客利用技术手段入侵系统或软件,窃取数据或破坏系统正常运行。
系统软件安全威胁
- 外部威胁:黑客攻击与病毒传播
- 黑客攻击:黑客利用漏洞入侵系统,窃取数据、破坏系统,严重威胁系统安全。
- 病毒传播:恶意软件通过网络传播,感染系统,导致数据丢失、系统崩溃等严重后果。
- 内部威胁:误操作与权限滥用
- 误操作:因疏忽大意或缺乏培训导致的错误操作,可能引入安全漏洞
- 权限滥用:内部人员利用被授予的权限进行非法活动,如数据泄露、篡改或破坏
- 供应链威胁:第三方组件漏洞
- 组件漏洞:第三方组件中的漏洞可能被恶意利用,影响整个系统的安全性
- 供应链攻击:攻击者可能通过供应链中的薄弱环节,植入恶意代码或篡改组件,对系统造成损害。
系统软件安全防护
常用安全技术与工具:
- 防火墙技术:部署防火墙来监控和过滤网络流量,阻止未经授权的访问和恶意攻击。
- 加密技术:使用加密技术对敏感数据进行加密处理,确保数据在传输和存储过程中的机密性和完整性。
- 安全漏洞扫描:利用安全漏洞扫描工具定期检测系统和软件中的安全漏洞,及时发现并修复潜在的安全威胁。
操作系统安全机制
操作系统安全威胁
安全威胁有3种分类方式:
- 按形成安全威胁的途径划分:不合理的授权机制、不恰当的代码执行、不恰当的主体控制、不安全的进程间通信(IPC)、网络协议的安全漏洞、服务的不当配置
- 按威胁的行为方式划分:切断、截取、篡改、伪造
- 按安全威胁的表现形式划分:逻辑炸弹、计算机病毒、特洛伊木马、后门(也叫天窗)、隐蔽信道
有关按安全威胁的表现形式划分下面比较详细讲一下:
-
逻辑炸弹:通常被添加在被感染应用程序的起始处,每当该应用运行时,检查是否满足运行炸弹的条件,如满足就执行炸弹的其余代码。造成终止机器、制造刺耳噪音、更改视频显示、破坏磁盘数据、利用硬件缺点引发硬件失效、使操作系统减慢或崩溃等。其特点是不能复制自身。
-
计算机病毒:能自我复制的一组计算机指令或程序代码,通过编译或者在计算机程序中插入这段代码,以达到破坏计算机功能、毁坏数据从而影响计算机使用的目的。其特点是隐蔽性、传染性、潜伏性、破坏性。
例如蠕虫病毒,一种常见的计算机病毒,是无须计算机使用者干预即可运行的独立程序,它通过不停的获得网络中存在漏洞的计算机上的部分或全部控制权来进行传播
-
特洛伊木马:自身是一段独立的计算机程序,表面上执行合法功能,实际上却完成用户不曾料到的非法功能,如释放病毒/蠕虫或其它隐藏在木马程序中的恶意代码,不具备自我复制能力。
其成功的条件在于:程序表面的行为方式不会引起用户的怀疑;攻击者必须设计出某种策略诱使受骗者接受这段程序;受害者必须运行该程序;特洛伊木马发作为攻击者带来实际收益
-
后门:是嵌在操作系统里的一段非法代码,攻击者利用该代码所提供的方法侵入操作系统而不受检查。
其特点是:由专门的命令激活,一般不容易发现。拥有攻击者所没有的特权,方便以后再次秘密进入或者控制系统。安装后门的目的就是渗透,只能利用操作系统的缺陷或者混入系统的开发队伍中进行安装
-
隐蔽信道:系统中不受安全策略控制的、违反安全策略的信息泄露路径
-
存储隐蔽信道:系统中两个进程利用不受安全策略控制的存储单元传递信息。
进程A通过改变存储单元的内容发送消息(如:增加或删除某文件);进程B通过观察相同存储单元的变化来接收消息(如:观察某文件是否存在)
-
时间隐蔽信道:系统中两个进程利用不受安全策略控制的系统在当前时间段内某方面的状态来传递信息。
进程A在该时间段内改变系统某状态(如:连续使用某一特殊I/O端口);进程B在该时间段内观察系统某状态(如:观察某一特殊I/O端口是否被使用)
-
操作系统安全的基本要求
操作系统种的几个概念:
- 主体(subject):操作系统中主动的实体,即某种行为的发起实体,包括用户、用户组、进程等
- 客体(object):操作系统中被动的实体,是主体行为的接受者,包括信息实体(如文件)、设备实体和进程等
- 安全属性:主体或客体的与安全相关的特定敏感标记,这些安全标记是实时访问控制的基础(敏感标记:表示实体安全级别并描述实体数据敏感性的一组信息)
- 系统事件:两个系统实体之间的交互,表示为<主体,操作,客体>
操作系统的安全需求:
- 保密性:原始信息的隐藏能力,让原始信息对非授权用户呈现不可见状态
- 完整性:信息在存储或传输过程中保持不被修改、破坏和丢失
- 可用性:系统能够正常运行或提供必要服务的能力
- 可靠性:系统提供信息的可信赖程度
操作系统的安全漏洞:
- 可能导致获取系统控制权的漏洞
- 可能导致获取隐私信息的漏洞
- 可能导致受到拒绝服务攻击的漏洞
操作系统安全基本要求的概念:
-
安全策略:有关如何管理、保护与分发敏感信息的法律、规定、条例和实施细则的集合,通常由一组安全规则描述
-
安全模型:对安全策略所表达的安全需求进行简单、抽象和无歧义的描述,包括形式化和非形式化安全模型。
安全模型是对安全策略所表达的安全需求的精确、无歧义抽象描述,在安全策略与安全实现机制的关联之间提供一种框架
-
安全机制:实现安全策略的具体方法及过程,通常在安全模型指导下设计实现。安全机制是安全策略的设计实现,是指导操作系统安全内核开发的重要依据
下面一节就专门讲各种各样的安全机制
-
安全内核:计算机系统中通过控制对系统资源的访问来实现安全策略的中心部分或技术
操作系统的常用安全机制
访问控制
访问控制是操作系统使用最频繁的安全机制。
定义:系统对用户身份及其所属的预先定义的策略组限制其使用数据资源能力的手段。
主要任务:
- 授权:确定可给予哪些主体访问客体的权限
- 确定访问权限:读、写、执行、删除、追加等访问方式及其组合
- 实施访问权限
主要功能:
- 保护存储在主机上的个人信息
- 保护重要信息的机密性
- 维护计算机内信息的完整性
- 减少病毒感染机会,从而延缓感染的传播
- 保证系统的安全性和有效性,以免受到偶然和蓄意的危害
三要素:
- 主体S(Subject):指提出访问资源具体请求的实体。是某一操作动作的发起者,但不一定是动作的执行者。可能是某一用户,也可以是用户启动的进程、服务和设备等。
- 客体O(Object):是指被访问资源的实体。包括被操作的信息、资源、对象等。可以是信息、文件、记录等集合体,也可以是网络上硬件设施、无限通信中的终端,甚至可以包含另外一个客体
- 策略A(Access Control Policy):是主体对客体的相关访问规则集合,即属性集合。体现了一种授权行为,也是客体对主体某些操作行为的默认
按访问控制的对象进行分类:
- 对文件的访问控制:读/拷贝(read-copy)、写/删除(write-delete)(附加、删除、修改)、 执行(execute)(通常同时具有读权限)
- 对目录的访问控制:读、写扩展(write-expand)(修改、附加、删除)
- 对目录的访问控制粒度:对目录而不对目录下文件实施访问控制、对目录下的文件而不对目录实施访问控制、对目录以及目录下的文件都实施访问控制(最好)
按访问控制的方式进行分类:
-
自主访问控制(DAC):是最常用的一类访问控制机制,用来决定一个用户是否有权访问一些特定客体的一种访问约束机制
- 允许访问对象的属主制定针对该对象访问的控制策略
- 每个客体有一个所有者,可按照各自意愿将客体访问控制权限授予其他主体
- 几乎所有的系统在自主访问控制机制中都包含文件、目录、IPC以及设备的访问控制
-
强制访问控制(MAC):系统强制主体服从访问控制策略,按照访问控制策略实施对客体的访问操作
- 系统中的每个进程、文件、IPC(消息队列、信号量集合、共享存储区)都被赋予相应的安全属性
- 安全属性只能由安全管理员或操作系统自动按照严格的规则来设置,不能随意修改。代表用户的进程不能改变自身的安全属性,也不能改变任何客体(包括用户所拥有的客体)的安全属性;进程不能将所代表用户的客体访问权限授予其它用户,来实现客体共享。
- 主体访问客体时:根据进程的安全属性和访问方式,比较进程的安全属性和客体的安全属性,从而确定是否允许进程对客体的访问
-
基于角色的访问控制(RBAC):通过定义角色的权限,并且对用户授予某个角色来控制用户的权限,从而实现了用户和权限的逻辑分离,方便了权限的管理。
下面有这个控制方式的原理和安全原则
有关RBAC,其基本原理如下:

- user(用户):每个用户都有不同且唯一的ID,用来进行识别,并被授予不同的角色
- role(角色):不同的角色具有不同的权限
- jurisdiction(权限):访问权限
- 映射关系(多对多):
- “用户->角色”映射:为用户分配不同的角色
- “角色->权限”映射:为角色分配不同的权限
RBAC的安全原则:
- 最小权限原则:将角色配置成其完成所需的最小权限集合
- 责任分离原则:通过调用相互独立且互斥的角色来完成敏感任务,例如:记账员和财务管理员共同参与过账操作
- 数据抽象原则:借助于抽象许可权这样的概念实现,如在账目管理活动中,可以使用信用、借方等抽象许可权,而不是使用典型的读、写、执行权限
对3种不同的访问控制机制进行优缺点对比:

认证机制
- 标识:操作系统能够通过内部识别码或标识符正确识别用户的身份,即用户向系统表明的身份。应具有唯一性,不能被伪造
- 鉴别:对用户所宣称的身份标识的有效性进行校验和测试的过程,用户声明自己身份的几种方法包括
- 证实自己所知道的:密码、身份证号、最喜欢的人名字等
- 出示自己所拥有的:智能卡、USBkey等
- 证明自己是谁:指纹、掌纹、声纹、视网膜、面部特征扫描等
- 表现自己的动作:签名、按键的速度与力量、语速等
- 授权:确定给予哪些主体存取哪些客体的权限,并实施这些存取权限
加密机制
- 数据传输加密:分为链加密和端加密
- 数据存储加密:分为文件级加密(对单个文件加密)和驱动器级加密(对逻辑驱动器上的所有文件加密)
最小特权管理
主流多用户操作系统中,超级用户一般具有所有特权,而普通用户不具有任何特权 。这样对于超级用户而言,若其口令被破解或发生误操作就会发生安全威胁。因此我们需要引入最小特权管理。
关于最小特权的定义:要求赋予系统中每个使用者执行授权任务所需的限制性最强的一组特权,即最低许可,可以限制因意外、错误或未经授权使用而造成的损害 。
最小特权原则:必不可少的特权
- 充分性:保证所有的主体都能在所赋予的特权之下完成所需要完成的任务或操作
- 必要性:在充分的前提下加以限制
即在系统中定义负责不同事物的人员,比如系统安全管理员、审计员、操作员、安全操作员、网络管理员。任何一个用户都不能获取足够的权利破坏系统的安全策略 ;也不应赋予某人一个以上的职责。
安全审计机制
几个概念:
- 审计:是一种事后(线下)分析法,一般通过对日志的分析来完成。对日志记录进行分析,能够以清晰的、能理解的方式表述系统信息
- 安全审计:对系统中有关安全的活动进行记录、检查及审核;认定违反安全规则的行为
- 审计事件:是系统审计用户动作的基本单位
如何实现审计系统:
- 日志记录器:收集数据,根据要审计的审计事件范围记录信息
- 分析器:分析数据,分析日志数据,使用不同的分析方法来监测日志数据中的异常行为
- 通告器:通报结果,将结果通知系统管理员或其他主体,为这些主体提供系统的安全信息,辅助对系统可能出现的问题进行决策
日志:记录事件或统计数据,提供关于系统使用及性能方面的信息。日志的分类如下:
- 系统日志:跟踪各种系统事件,记录由系统组件产生的事件
- 应用程序日志:跟踪各种系统事件,记录由系统组件产生的事件
- 安全日志:记录安全相关的关键安全事件
存储、运行、IO保护
存储保护
存储保护即保护用户存储在存储器中的数据
- 保护单元与保护精度:字/块/页面/段
- 系统要求:单道系统 vs 多道系统 vs 多用户系统
存储器管理和存储保护之间的关系:
- 存储基本概念:虚拟地址空间、段
- 基于内存管理的访问控制
- 系统段与用户段
- 基于物理页号的识别(秘钥机制)
- 基于描述符的地址解释机制(用户模式 vs 系统模式)
运行保护

等级域保护机制:
- 保护某一环不被其外层环侵入
- 允许在某一环内的进程能够有效控制其外层的环
与进程隔离机制不同:
- 在任意时刻,进程可以在任何一个环内运行
- 保护进程免遭在同一环内同时运行的其它进程对该进程的破坏
IO保护
I/O操作一般是特权操作,操作系统对I/O操作进行封装,提供对应的系统调用。将设备看成一个客体,对其应用相应的访问控制规则:读写、针对从处理器到设备间的路径
安全操作系统的设计与实现
可信平台模块TPM:建立个人电脑的可信计算概念;在计算和通信系统中广泛使用基于硬件安全模块支持下的可信计算平台,以提高整体的安全性
可信密码模块TCM:中国标准的TPM
TPM/TCM安全芯片的用途:
- 存储、管理BIOS开机密码以及硬盘密码
- TPM/TCM安全芯片可以进行范围较广的加密
- 加密硬盘的任意分区
核心理念是基于TPM/TCM这样一个硬件核心,配合上可信软件栈(TSS),来实现一个信任根。即使操作系统不可信,仍然可以在其中执行可信的、不被干扰的某项任务。比如:在不可信的操作系统上安全地存储密钥
ARM TrustZone:ARM TrustZone®技术是系统范围的安全方法,针对高性能计算平台上的大量应用,包括安全支付、数字版权管理、企业服务和基于Web的服务
核心设计思想是“隔离” ,将系统运行环境划分为可信的和普通的两部分:
- 可信的部分:TEE (Trusted Execution Environment)
- 普通的部分:REE (Rich Execution Environment)
SGX:Intel SGX技术是英特尔于2015年推出的一项安全技术,允许用户级代码分配专用内存区域(称为隔区,enclave),以免受到拥有更高权限的进程的影响
安全特性:
-
应用程序分为两部分:安全部分和非安全部分
-
应用程序启动 enclave,它被放置在受保护的内存中,enclave只有在安全条件下才可以访问
-
当调用enclave函数时,只有enclave内部的代码才能查看其数据,并始终拒绝外部访问,当调用结束时,enclave的数据会留在受保护的内存中
应用程序封装在enclave中的安全操作,OS和BIOS等特权系统都无法访问
安全执行环境是宿主进程的一部分:
- 应用程序包含自己的代码、数据和 enclave
- enclave 也包含自己的代码和自己的数据
- SGX 保护enclave代码和数据的机密性和完整性
- enclave入口点是在编译期间预定义的
- 支持多线程
- enclave可以访问其他应用程序的内存,但反过来不行
各操作系统安全性分析
Windows操作系统
Windows系统概述
介绍:Microsoft Windows是美国微软公司以图形用户界面为基础研发的操作系统,主要运用于计算机、智能手机等设备,是全球应用最广泛的操作系统之一。
里程碑:Windows 95引入图形用户界面,Windows XP增强稳定性和安全性,Windows 10和11继续优化用户体验。
Windows NT系统:Windows NT(New Technology)是微软公司第一个真正意义上的网络操作系统,发展经过NT 3.0-10.0等众多版本,并逐步占据了广大的中小网络操作系统的市场。
Windows NT支持多种网络协议,内置Internet功能,还支持NTFS文件系统。(使用NTFS的好处:可以提高文件管理的安全性,用户可以对NTFS系统中的任何文件、目录设置权限,这样当多用户同时访问系统的时候,可以增加文件的安全性)
Windows系统架构:分为用户模式和内核模式,基于CPU运行状态划分。即用户模式下,应用程序代码运行在CPU非特权模式;内核模式下,内核代码运行在CPU特权模式。

用户模式即运行应用程序的模式,应用程序可以访问一些系统资源,如文件系统、网络、进程和线程等,但不能直接访问内核模式或底层硬件设备。
用户模式的组成如下:
- 用户进程:用户应用程序相关。用户应用程序无法直接调用原生的Windows操作系统服务,而是需要**通过一个或多个子系统动态链接库(DLL)**调用
- 服务进程: Windows服务相关,如Task Scheduler和Print Spooler服务
- 系统进程:静态或硬编码的进程,如非Windows 服务的登录进程和会话管理器
- 环境子系统服务进程:实现操作系统环境的支持部分的进程(环境是指呈现给用户和程序员的、操作系统中可进行个性化的部分)
内核模式下一切程序都可运行。任务可以执行特权级指令,对任何I/O设备有全部的访问权,还能够访问任何虚地址和控制虚拟内存硬件
内核模式的组成如下:
- 执行体:包含操作系统的基础服务,例如内存管理、进程和线程管理、安全性、I/O、网络以及进程之间通信
- Windows内核:包含底层操作系统函数,例如线程调度、中断和异常分发、多处理器同步。还提供了一系列的例程和基本对象,执行体的其他部分会使用它们实现更高层次的功能
- 设备驱动程序:包括将用户I/O函数调用转换为特定硬件设备I/O请求的硬件设备驱动程序,以及诸如文件系统和网络驱动程序等非硬件设备驱动程序
- 硬件抽象层(HAL,hardware abstraction layer):负责将内核、设备驱动程序以及Windows执行体的其他部分与和具体平台有关的差异进行隔离
- 窗口和图形系统:用于实现用户界面(GUI)功能,例如处理窗口、用户界面控件以及进行绘制
- 虚拟机监控程序层:只包含虚拟机监控程序本身,由多种内部层和驱动程序组成,如自己的内存管理器、虚拟处理器调度器、中断和计时器管理、同步例程、分区(虚拟机实例)管理、分区间通信(IPC)等,不包含其他驱动程序或模块
Windows安全组件

Windows安全性由核心组件和数据库实现。
标识:辨认你是谁的方法
-
安全账户管理器(Security Accounts Manager,SAM):维护SAM数据库,负责管理本机定义的用户名和组等信息
-
SAM数据库:由SAM管理,其中包括已定义的本地用户、组以及密码和其它属性信息。
该数据库存储在注册表HKEY_LOCAL_MACHINE\SAM键下,受到ACL保护。
磁盘保存位置:%systemroot%\system32\config\sam;一个比较复杂的结构;SAM在系统启动后就处于锁定状态,用户无法擅自更改其内容;SAM不听从用户的指挥,只听从LSASS的差遣
鉴别:根 据 获 得的 标 识 信息 验 证 客户的身份
- 交互式登录管理器(Interactive Logon Manager,即Winlogon):管理交互式登录会话。当用户登录时,创建用户的第一个进程
- 登录用户界面(Logon User Interface,LogonUI):为用户提供向系统验证自己身份所需的用户界面。使用凭据提供程序,通过多种方式查询用户凭据
- 凭据提供程序(Credential Provider,CP):是一种在LogonUI进程中运行的进程内COM对象。用于获取用户的用户名、密码、智能卡PIN码、生物验证数据(如指纹、面部识别数据)等
- 身份验证包(Authentication Package,AP):检查特定用户名与密码(或者用于提供凭证的其它任何机制)是否匹配,进而对用户进行身份验证
授权与审计:授权用于设置不同对象的访问权限(ACL);审计用于对整个过程(标识鉴别、对象授权、访问控制)进行审核
-
本地安全机构子系统服务(Local Security Authority Subsystem Service, LSASS)
- 负责本地系统安全策略:允许哪些用户登录到计算机、密码策略、为用户和组分配特权、系统安全审核设置
- 负责用户身份验证
- 负责将安全审核信息发送给事件日志
-
LSASS策略数据库:包含了本地系统安全策略设置,存储在注册表HKLM\SECURITY键下一个受ACL保护的区域内
-
内核安全设备驱动程序(Kernel Security Device Driver,KSecDD)
-
运行于内核模式
-
实现了高级本地过程调用接口,其它内核模式安全组件,包括加密文件系统(Encryption FileSystem,EFS),可以用来在用户模式下与LSASS通信
-
访问控制:根据用户标识和对象的ACL进行访问控制
- 安全引用监视器(Security Reference Monitor, SRM):或称安全参考监视器,定义代表安全上下文的访问令牌数据结构。针对对象执行安全访问检查、操作特权(用户权限)检查,以及生成所产生的各类安全审核信息
- APPLocker:该机制供管理员决定用户和组允许使用哪些可执行文件、DLL和脚本。包含一个驱动程序(%SystemRoot%\System32\Drivers\AppId.sys)和一个服务( %SystemRoot%\System32\AppIdSvc.dll)。运行于标准SvcHost进程中
- APPContainer:提供一个限制性的进程执行环境(或称容器)。 应用的进程及其子进程在轻型应用容器中运行,它们只能访问专门授予它们的资源
Windows访问控制
系统通过查看访问者的访问令牌与被访问对象的安全描述符中的内容来确定访问者是否能访问对象
访问令牌(Access Token):包含有关已登录用户的信息
- 用户登录时 ,系统会对用户的帐户名和密码进行身份验证。如果登录成功,系统将创建访问令牌。代表此用户执行的每一个进程都将具有此访问令牌的副本
- 访问令牌包含的内容:包含安全标识符,用于标识用户的帐户以及该用户所属的任何组帐户。包含用户或用户组拥有的权限列表,当进程尝试访问安全对象或执行需要特权的系统管理任务时,系统使用此令牌来标识关联的用户
安全描述符(Security Descriptor):包含用于保护安全对象的安全信息
- 创建安全对象时,系统会为其分配一个安全描述符,其中包含其创建者指定的安全信息,如果未指定任何安全信息,则为其分配默认安全信息
- 应用程序可以使用函数检索和设置现有对象的安全信息
访问控制列表(Access Control List, ACL):表示用户(组)权限的列表
访问控制项(ACE):是访问控制列表(ACL)中的元素,每个ACE控制或监视指定受托者(Trustees)对对象的访问,用于指定特定用户/组的访问权限。一个ACL可以包含零个或多个ACE
访问控制列表ACL可分为自主访问控制列表DACL,系统访问控制列表SACL:
- 自主访问控制列表(Discretionary Access Control List, DACL):DACL标识是否允许或拒绝访问安全对象:当进程尝试访问安全对象时,系统将检查该对象的DACL中的ACE,以确定是否授予对该对象的访问权限
- 所有ACE所赋予的权限累加就组成该ACL最终可授予的访问权
- 若SD中不存在DACL:每个用户都可获得对象的完整访问权
- 若DACL为空(即没有ACE):任何用户都无法获得对象访问权
- 系统访问控制列表(System Access Control List, SACL):SACL其实就是一个审计中心,这个列表里面列举着哪些类型的访问请求需要被系统记录。一旦有用户访问一个安全对象,其请求的访问权限和SACL中的一个ACE符合,那么系统会记录这个用户的请求是被拒绝还是被允许
Linux操作系统
Linux系统:是一套可以免费使用和自由传播的类Unix操作系统,主要用于基于Intel X86系列CPU的计算机上
Linux系统用户管理
Linux系统将用户分为超级用户和普通用户两个类别。
超级用户:root
- 进程控制:改变进程优先级,向任何进程发送任何信号,修改系统硬件限制(如最大CPU时间、最大打开文件句柄数等),调试任何进程(使用strace等),向运行中内核动态加载、卸载模块……
- 设备控制:格式化硬盘、关机和重启服务器、读取和修改任何内存区域、设置日期和时间
- 网络控制:在1~1024端口上运行网络服务,配置和重新配置网络,将网卡设置成混杂模式,设置网络防火墙(如iptables)
- 文件系统控制:读取、修改、删除系统上的任何文件,运行任何程序,挂装和卸载文件系统、启用和禁止磁盘配额等
- 用户控制:增加和删除用户、用户组,为任何用户(包括超级用户自己)修改密码和改变属性
普通用户:只能在高端口(1024以上)监听和运行网络服务、只能修改自己的密码等
用户管理中的两个重要文件:
/etc/passwd:记录系统中所有用户的信息,共7个字段,以“:”隔开
- 帐号名称
- 密码:放置于/etc/shadow,用x代替
- UID:系统创建用户时会给每个用户分配一个UID。0为系统管理员,其他账号UID为0时拥有root权限;1~499为系统账号;500~$为一般用户登录的账号。
- GID:与/etc/group有关,如果建立用户时,不指明所创建的用户属于哪个组,系统会自动建立一个跟用户名同名的组
- 用户信息说明
- 主文件夹
- shell类型
/etc/shadow:存放系统中所有用户的密码
- 账号名称
- 经过加密的密码
- 最近更改密码的日期 (从1970年月1日开始到当前的日期)
- 密码不可被更改的天数
- 密码需要被更改的天数(99999计算为273年,表示没有限制之意)
- 密码需要更改期限前的警告天数
- 密码过期后的宽限日
- 账户失效日期 (从1970年月1日开始到当前的日期)
- 保留
Linux系统访问控制

文件基本属性:

-
第0个字符:代表文件类型是目录、文件或链接文件等
- d :目录
- - :文件
- l :链接文档(link file);
- b :为装置文件里面的可供储存的接口设备(可随机存取装置);
- c:为装置文件里面的串行端口设备,例如键盘、鼠标(一次性读取装置))
-
第1-3位确定属主(该文件的所有者)拥有该文件的权限
-
第4-6位确定属组(所有者的同组用户)拥有该文件的权限
-
第7-9位确定其他用户拥有该文件的权限
- r 代表可读(read) -> 数字4
- w 代表可写(write) -> 数字2
- x 代表可执行(execute) -> 数字1
- 这三个权限的位置不会改变,如果没有权限,就会出现减号
文件访问流程:
当用户程序需要访问文件时,便会调用相应的系统调用如open()。open系统调用在执行时会通过系统调用服务例程进入内核,然后调用VFS中相关操作对该请求进行处理
虚拟文件系统VFS:对高层进程和应用程序隐藏了Linux支持的所有文件系统的区别,不论文件系统是存储在本地设备,还是需要通过网络访问远程设备
当要访问文件对应的内核数据时,内核会先检查该用户是否具有访问权限,如果权限检查通过,此时才能真正访问相应的数据,否则拒绝用户的请求。
在进行权限检查时,依次会进行普通的权限检查、DAC检查和MAC检查,如果所有的检查均通过则允许用户访问该文件。
在进行DAC检查时,VFS会根据用户请求的文件的类型来调用相应文件系统中实现的函数来从文件的扩展属性中查找文件的ACL权限,如果文件中指定了相应的权限,则检查通过,否则函数直接返回,即拒绝用户的访问请求
移动操作系统
三种移动操作系统对比

宏内核与微内核:
- 宏内核(Monolithic Kernel)是一个大内核(单内核),是个单独的二进制大映象,内部再被分为若干模块,模块间的通讯是靠调用函数实现的。单内核所有的服务都在一个内核空间上运行,运行效率高,但如果其中一个模块出现 bug,容易导致整个系统崩溃
- 微内核(Micro Kernel)是一种只提供必要服务的操作系统内核,比如任务、线程、交互进程通信、内存管理等等。所有其他服务及驱动都在用户模式下运行,处理这些服务等于运行程序,每个服务都在自己的地址空间运行

鸿蒙系统
华为主导开发的一款全新的面向全场景的分布式操作系统,创造一个超级虚拟终端互联的世界,将人、设备、场景有机地联系在一起,将消费者在全场景生活中接触的多种智能终端,实现极速发现、极速连接、硬件互助、资源共享,用合适的设备提供场景体验。
- 全球排名第三的智能手机操作系统,开创性的物联网领域第一款操作系统
- 提供强大的分布式体系,带来的稳定、快速的用户体验以及多设备协同体系
- 具备安全的架构设计和内置的安全功能,包括受保护的内核、安全存储和用户身份验证等
安卓系统
一种基于Linux内核(不包含GNU组件)的自由及开放源代码的移动操作系统。主要应用于移动设备,如智能手机和平板电脑。
- 每个应用都以一个系统识别身份运行(Linux用户ID与群组ID)
- 安全特性包括应用权限管理、应用隔离和硬件级别的安全保护等
其核心安全机制如下:
- 访问控制:权限管理:通过给不同的应用程序分配不同的权限,保证不同的应用程序可以访问不同的数据;敏感权限管理:对一些敏感操作进行审核和监管
- 沙箱模拟:假定应用软件之间以及用户自行安装的应用程序是不可信的,需要将应用程序置于“沙箱”之内以限制应用程序的功能,实现应用程序之间的隔离
- 设定允许或拒绝API调用的权限
- 控制应用程序对资源的访问,如访问文件,目录,网络,传感器等
苹果系统
由苹果公司开发的移动操作系统,与苹果的macOS操作系统一样,属于类Unix的商业操作系统,主要是给iPhone、iPod touch以及iPad使用
其内核架构由Mach、BSD和IOKit组成:

- Mach:微内核,微内核可以提高系统的模块化程度,提供内存保护的消息传递机制
- BSD:是对 Mach再次封装的宏内核, 提供了更现代、更易用的内核接口。宏内核(单内核)性能更高, 在高负荷状态时依然保持高效运作
- IOKit:是硬件驱动程序的运行环境,包含电源、内存、CPU 等信息
其安全机制如下:
-
更小的受攻击面:尽可能降低攻击者可以访问(尤其是可以远程访问)的代码量
-
精简的操作系统:精简若干应用
-
权限分离:使用用户、组和其他传统UNIX文件权限机制分离各进程。易被攻击的程序会被限制在用户mobile身份下运行;而重要的系统进程会在root身份下运行。
-
代码签名机制:所有的二进制文件(binary)和类库在被内核允许执行之前都必须经过受信任机构(比如苹果公司)的签名
-
数据执行保护(DEP:Data Execution Prevention):处理器能区分哪部分内存是可执行代码以及哪部分内存是数据,而DEP不允许数据的执行,只允许代码执行。
当漏洞攻击试图运行有效载荷时,它会将有效载荷注入进程并执行该有效载荷。DEP会让这种攻击行不通,因为有效载荷会被识别为数据而非代码
-
地址空间布局随机化(ASLR:Address Space Layout Randomization):二进制文件、库文件、动态链接文件、栈和堆内存地址的位置全部随机化
当系统同时具有DEP和ASLR机制时,针对该系统编写漏洞攻击代码的一般方法完全无效(攻击者需要两个漏洞,一个用来获取代码执行权,另一个用来获取内存地址以执行ROP攻击)
-
沙盒机制:面向进程可执行的行动提供更细粒度的控制。限制恶意软件对设备造成的破坏,即限制恶意软件的有效载荷在沙盒可访问的内容中
系统日志攻击检测与安全分析
这节是课设内容。
系统日志
- 系统实体:主要3种实体,即文件、进程、网络连接,用不同的图形表示
- 系统事件:<主体,操作,客体>
- 主体:系统进程实体,如浏览器
- 操作:事件动作,如读/写
- 客体:系统文件、进程或网络连接实体。根据客体划分,系统事件可称为文件事件、进程事件和网络事件

溯源图与溯源分析
溯源图:
- 系统实体(主体和客体)用顶点表示
- 事件类型用边表示:边的尾部连接主体,头部连接客体
- 在不同的时间,2个顶点之间可以有多条边相连
因果分析:用于推断系统审计事件中的因果依赖,并形成因果依赖图。依赖图为有向图:节点为系统实体,边为系统审计事件
- 对于依赖图G(E, V),单个系统审计事件为e(u, v),其中u ∈ V, v ∈ V, e ∈ E
- 边的方向代表数据流的方法(即从u流动到v),边的属性包括开始时间(e.st)和结束时间(e.et)
- 给定两个节点n1和n2,存在n2因果依赖于n1,如果存在:两条边e1(n1, v1)和e2(v2, n2)满足v1 = v2,以及(e1在e2结束前开始)
网络安全
概述
网络存在不安全的原因:
- 自身缺陷
- 开放性:网络使用公开的协议;其远程访问的特性使得攻击无需线下;连接是基于主机上的社团彼此信任的原则
- 黑客攻击
网络面临的四种威胁:
- 截取:从网络上窃听他人的通信内容。
- 切断:有意中断他人在网络上的通信。
- 篡改:故意篡改网络上传送的报文。
- 伪造:伪造信息在网络上传送。
威胁的分类:
- 被动攻击:截获信息的攻击,攻击者只是观察和分析某一个协议数据单元 PDU (ProtocolData Unit)而不干扰信息流。
- 主动攻击:更改信息和拒绝用户使用资源的攻击,攻击者对某个连接中通过的 PDU 进行各种处理(更改报文流、拒绝报文服务、伪造连接初始化)
计算机通信安全的目标:
- 机密性:消息不泄露给未授权的实体。
- 完整性:只有被授权后才能进行资源修改。
- 可用性:即便遭受攻击,攻击者也不能占用所有资源而阻碍授权者工作。
- 可追溯性:即使出现安全问题,也有可供调查的依据和手段
- 抗抵赖性:对导致安全事件出现的行为不能抵赖
- 真实性:能判断消息的来源,能鉴别那些伪造来源的消息
- 可控性:在授权范围内,可以控制信息的流向和行为
因特网安全协议
网络层安全协议
体现于完整性保护和机密性保护(对所有在 IP 数据报中的数据加密)
IPsec 协议:
-
鉴别首部 AH (Authentication Header):鉴别源点、检查数据完整性,不提供保密性
在传输过程中,中间路由器不查看 AH 首部;当数据报到达终点时,目的主机处理 AH 字段,以鉴别源点和检查数据报的完整性
-
封装安全有效载荷 ESP (Encapsulation Security Payload):鉴别源点、检查数据完整性、提供保密性
IPsec的工作方式:传输模式、隧道模式
安全关联 SA (Security Association):建立一条从源主机到目的主机网络层的逻辑连接—— IPsec 将无连接的网络层转换为具有逻辑连接的层。定义实体间如何使用安全服务进行通信
单向连接:在一次通信中,IPSec需要建立两个SA,分别用于入站通信、出站通信
安全关联SA的组成(三元组):
- 安全协议(使用 AH 或 ESP)的标识符;
- 此单向连接的源 IP 地址;
- 安全参数索引 SPI (Security Parameter Index):32 位的连接标识符:每个SA用唯一的SPI索引标识;每一个 IPsec 数据报都有一个存放 SPI 的字段,接收端根据SPI值决定使用哪个SA
安全关联的创建——IKE (Internet Key Exchange):
- 主模式协商
- 通信双方的身份认证:共享密钥或公钥证书
- 协商IKE SA:以保护后继的IPsec SA协商过程
- 快速模式协商:IPsec SA
传输层安全协议
安全套接层 SSL (Secure Socket Layer):
- 是一种在应用层协议和TCP/IP之间提供数据安全性分层的机制,为TCP/IP连接提供数据加密、服务器认证、消息完整性以及可选的客户机认证
- SSL 由Netscape于1994年开发,广泛应用于基于万维网的各种网络应用(但不限于万维网应用,如http、telnet、NNTP、FTP等 )
- 1996年发布 SSL 3.0,成为 Web 安全的事实标准
- 在发送方,SSL接收应用层的数据(如 HTTP 或 IMAP 报文),对数据进行加密,然后将加了密的数据送往 TCP 套接字;在接收方,SSL从 TCP 套接字读取数据,解密后将数据交给应用层
传输层安全 TLS (Transport Layer Security):1999年,IETF 在 SSL 3.0 基础上推出了传输层安全标准 TLS,为所有基于 TCP 的网络应用提供安全数据传输服务
SSL的功能:
- SSL服务器鉴别:允许用户证实服务器的身份——具有 SSL功能的浏览器维持一个表,维护可信赖的认证中心CA和它们的公钥
- SSL客户鉴别: SSL的可选安全服务,允许服务器证实客户的身份
- 加密的SSL会话:客户和服务器交互的所有数据都在发送方加密,在接收方解密
应用层安全协议
PGP (Pretty Good Privacy):提供电子邮件的保密性、发送方鉴别、完整性(一次一密)
工作过程(A向B发邮件明文X)
- 对明文X,计算MD5摘要H,用自己私钥签名形成D(H),拼接原文得到报文(X+D(H))
- 用自己生成的一次性密钥加密(X+D(H))
- 用B公钥加密自己生成的一次性密钥
- 向B发送加了密的(X+D(H))、加密后的一次性密钥
访问控制和防火墙
访问控制
访问控制:按用户身份来限制用户对某些信息项的访问,或限制对某些控制功能的使用——限制访问主体(如用户、进程等)对访问客体(如文件、系统等)的访问权限
访问控制的三要素:主体、客体、权限——形成访问控制矩阵
访问控制矩阵的实际存储:
- 访问控制表:每个客体有一个访问控制表
- 访问能力表:每个主体有一个访问能力表
- 授权关系表:访问控制矩阵中的非空元素
访问控制策略:
- 自主访问控制(Discretionary Access Control,DAC):主体可自主地将其拥有客体的访问权限全部或部分地授予其它主体
- 强制访问控制(Mandatory Access Control,MAC):系统将主体和客体分成不同的安全等级,主体和客体之间的安全等级符合一定要求,才可进行访问
- 基于角色的访问控制策略:权限分配给角色,通过用户承担的角色来授予一定的权限
这部分在操作系统的访问控制中也有涉及
防火墙
防火墙 (firewall) :是由软件、硬件构成的系统,一般部署需要保护的内部网络出口处,对该网络与外部网络之间的访问实施安全控制
防火墙的分类:
- 网络级防火墙:对网络报文进行分析,利用报文过滤技术,阻止不合理的网络连接或数据传递
- 应用级防火墙:使用应用网关或代理服务器技术,对特定的网络应用进行分析,以阻止非法的网络应用
防火墙的技术发展:
- 包过滤:通过ACL检查数据流中每个数据包的源宿地址,端口号、协议状态等来确定是否允许该数据包通过
- 应用代理:工作在OSI模型的应用层,主要使用代理技术来阻断内部网络和外部网络之间的通信,达到隐藏内部网络的目的
- 状态检测:也被称作自适应防火墙或动态包过滤防火墙
- UTM(Unified Threat Management,统一威胁管理) ,将IDP/IPS、反病毒、反垃圾邮件、URL过滤等功能集成在一起的防火墙设备产品
- NGFW(Next Generation Firewall) ,即下一代防火墙,该防火墙不再基于端口而是基于应用程序来执行相关的安全策略
常见攻击类型和入侵检测
常见攻击类型:漏洞扫描、端口扫描、网络嗅探(sniffer)、拒绝服务攻击、欺骗攻击(ARP欺骗、IP欺骗、DNS欺骗等)
入侵检测:指通过行为、安全日志、审计数据或其它网络上可获得的信息进行操作,检测到对系统的攻击或攻击企图
入侵检测系统IDS的分类:
-
依据数据来源的不同
- 主机入侵检测
- 网络入侵检测
- 混合分布式入侵检测系统
-
依据数据分析方法的不同
- 基于异常(如:机器学习)的入侵检测系统
- 基于误用(如:规则)的入侵检测系统

IDS vs IPS vs FW vs WAF四种技术的对比

安全编程
概述
为什么要安全编程?
- 保障数据安全:防止数据泄露、篡改和非法访问,确保用户隐私和业务连续性。
- 防范网络攻击:提高代码安全性,减少漏洞,降低被黑客攻击的风险。
- 提升软件质量:通过安全编程实践,减少因安全问题导致的软件故障和修复成本
安全编程原则
-
了解威胁模型:威胁模型即攻击者是谁以及他们拥有什么资源的模型。要搞明白谁攻击我、为什么攻击我。
-
最小特权原则:考虑实体或程序需要什么权限才能正确完成工作。将权限限制为上下文的最小值。
在评估系统设计的安全性时,可以使用可信计算基(Trusted Computing Base, TCB)。安全要求TCB是正确的、完整的(无法绕过)、本身是安全的(不能被篡改)

-
责任分离:也称为分布式信任。顾名思义就是负责A模块的人无权访问或者控制B模块功能。
-
确保完全调解/仲裁:确保每个接入点都受到监控和保护
参考监视器:所有访问都必须通过的单点(比如机场安检,在网络中比如防火墙)。参考监视器要具备的特性是正确性(可验证)、完整性(不能绕过)、安全性(不可篡改)
-
考虑人为因素:是个人都想怎么方便怎么来,然后人还容易犯错
-
从不发明安全技术:不要创建自己的安全技术,始终使用经过验证的组件。说白了就是自己菜没金刚钻不揽瓷器活。
-
安全即经济:成本/收益分析经常出现在安全方面:防御的预期收益应该与攻击的预期成本成正比。好钢用在刀刃上!
安全编程实践
SQL注入防护:
- 参数化查询:使用参数化查询防止SQL注入,确保输入值被正确处理,而非直接嵌入SQL语句
- 最小权限原则:遵循最小权限原则,限制数据库账号的权限,避免攻击者通过SQL注入获得更高的权限
跨站脚本(XSS)防护:
-
输入验证:对用户输入进行严格的验证和过滤,防止恶意脚本的注入。
对所有来自用户的输入进行严格的验证,确保它们符合预期的格式和类型;使用白名单技术来允许特定字符或字符集,并拒绝所有其他字符;清理或转义输入数据中的特殊字符(如<, >, &, ", ', (, ), #等),以防止它们被解释为HTML或JavaScript代码的一部分
-
输出编码:对输出到HTML页面的数据进行适当的编码,确保恶意脚本不会被浏览器执行。
在将用户输入的数据显示回浏览器之前,对其进行适当的HTML编码或JavaScript编码。这可以防止浏览器将用户输入当作HTML或JavaScript代码执行,而是将其显示为纯文本
-
使用HTTP头:设置适当的HTTP头,如Content-Security-Policy,来限制外部资源的加载,减少XSS攻击的风险。
CSP是一个额外的安全层,用于检测并减少某些类型的攻击,包括数据注入攻击。通过设置CSP,可以指示浏览器仅从可信来源加载资源,如脚本、样式表和字体
语义分析

【编译原理期末版】第五章 语法制导翻译(1)思路清晰,快速判断综合属性和继承属性_哔哩哔哩_bilibili
【编译原理期末版】第五章 语法制导翻译(2),构造注释分析树,计算翻译结果,指出语义功能_哔哩哔哩_bilibili
编译原理第7章-语法制导的语义计算-1_哔哩哔哩_bilibili
语义分析的结果就是为了产生中间代码,而我们希望在语法分析的同时就完成语义分析的相关内容,故称为语法制导翻译。
基于属性文法的语义计算
属性文法:为文法符号(终结符、非终结符)配置若干属性,比如类型、值等;为产生式配置一组属性的语义动作,用于对属性进行计算与传递。

对于一个给定的输入串(比如),我们先构建其语法分析树,然后用语义规则来计算分析树各节点的属性值。把这些属性值都标在分析树上就是带注释的语法树。

属性可以分为两类:综合属性和继承属性。
-
综合属性是来自于子节点属性或自己的属性算出来的,在语法树中体现为自下而上传递信息。
-
继承属性来自于父节点与兄弟节点,在语法树中体现为自上而下传递信息。

比如这里第一个,其取值来自它的兄弟,就属于继承属性;后面的,其取值来自它的父亲,也是继承属性。
-
仅使用综合属性的属性文法叫S-属性文法;含有综合属性也含有继承属性的文法叫L-属性文法。
对于终结符而言,其可以具有综合属性,但是其综合属性直接由词法分析器给定,不会有计算终结符属性的语义规则;终结符没有继承属性。
对于非终结符而言,其综合属性的计算一定是当改非终结符位于产生式左边时计算。
比如产生式,其中的在产生式右边,那么其计算一定是在中完成。
那么属性值的计算应该按照什么顺序?
课上讲的是通过依赖图的方式完成。当然也有其他方法。
属性依赖:对于属性b,其要通过属性计算出来,就称属性b依赖于属性。
依赖图就是一个描述分析树中节点属性依赖关系的有向图。依赖图中每个节点代表一个属性,每条边代表谁依赖于谁(比如属性a依赖于属性b,那么就有一条从b指向a的边)

上图中依赖于和,所以由和有指向的边。
一个依赖图的任意拓扑排序即一个语法树中节点的语义规则计算有效顺序。
拓扑排序的流程是这样的:对于有向无环图,选择一个入度为0的节点输出,并在图中删除该节点和所有以它为起点的边。重复该操作使得图为空即可。
例题

利用上面的语义规则给出这个表达式的求值顺序:
-
用虚线画语法树

-
往终结符或者非终结符旁边标属性。一般综合属性标右边,继承属性标左边。

-
根据依赖关系画出依赖图,就能得出计算顺序(这里给每个属性标号方便查看,其中画波浪线的表明顺序可调换)

语法制导翻译SDT
把语义规则放在{}里,插入到产生式的右侧合适位置上,进一步细化语义计算的时机。
SDT可以看作是对 SDD 的⼀种补充,是 SDD 的具体实施⽅案,SDT 显式 地指明了语义规则的计算顺序,以便说明某些实现细节
在课上讲的是针对L-属性文法进行SDT。首先是如何将原先的产生式和语义规则间的映射关系转换为SDT:

- 对于继承属性,如这里的,为继承属性,这种就放在产生式右部的前面。还有这里的也是一样的
- 对于综合属性,就直接放在整个产生式右部的后面。
例子

- L_en和L_bd不依赖于其他属性,它们可以被分配到产⽣式的第⼀个语义动作中
- 中为继承属性,放在C的前面
- 中为继承属性,放在C的前面
- 中为继承属性,放在S1的前面
- 那句是综合属性,放最后

递归下降分析进行翻译
仍然以上面那个while为例:
1 | string S(label next) { |
一般而言,在写递归下降程序时,基本套路是这样的:
- 为每个非终结符A都构造一个函数。函数的参数是A的每个继承属性;返回值为A的综合属性
- 在程序中,首先要为出现在A产生式右边的每个文法符号的每个属性都设置一个局部变量。用
D:表示
例子
首先是这两行,继承属性为,综合属性为,则程序为:
1 | T'syn T'(token, T'inh){ |
比如这里T这行,没有T的继承属性,T的综合属性是,所有的局部变量为,则其递归下降程序如下:
1 | Tval T(token){ |
最后F那行,没有继承属性,综合属性是。
1 | Fval F(token){ |
LL、LR语法分析
TODO
11.15课2
中间代码生成
中间代码
中间代码:顾名思义就是在编译过程中产生的代码。从广义上说其包括抽象语法树AST、控制流图CFG等;从狭义上说就是一种中间表示IR。
如何实现中间表示:
-
三地址码:每个指令最多只有3个操作数(当然2个也行)
比如a=b+c,abc就是3个操作数;a+b+c这种没有等号的就不是指令

-
静态单赋值形式SSA:每个变量在程序中只会被使用一次,有利于进行某些代码优化

表达式的翻译

类型检查
类型检查有两种形式:综合和推导
类型综合
类型函数,其返回值为一个类型。记为两个type值,存在一个映射关系,x的type值为s,则f(x)的type值为t。
类型转换:有两种转换方式
- 自动类型转换:由编译器自动完成
- 强制类型转换:由人指定

语义动作:
max(t1, t2):在拓宽类型情况下,返回t1和t2哪个更精度高的类型。比如t1是int类,t2是double类,返回值就是double。widen(a, t, w):将类型为t的地址a中的内容转换成w类型的值,并返回a

类型推导
类型推导即根据语言构造的使用方式确定语言构造的类型。
如果是一个表达式,那对于类型变量a和b,f有映射关系且x的类型为a,则的类型为b。
多态函数:支持多模态的输入
1 | fun length(x) = if null(x) then 0 else length(tl(x)) + 1; |
-
列表x:该列表内的元素一定是统一的,比如都是int这种
-
length:该函数用于确定列表的长度(列表中元素的个数)
即,其中为某类型变量。
-
null(x):用于判断列表空或非空,其返回bool类型
-
tl(x):把列表中第一个元素去除,返回一个新列表
控制流
控制流即程序指令的执行顺序,是通过布尔表达式来实现的。
常见的布尔表达式有:
- $B\rightarrow !B $
- ,这里的E是数学表达式,是关系运算符(<,<=,==这种)
- 优先级(高到低):否、与、或
短路(跳转)代码:

注意这里的优先级!第1行的意思就是如果x<100是True,而后面那个x>200&&x!=y无所谓是啥,if一定是true,就直接做L2处的赋值语句。
**控制流语句:**有3种
- S ⟶ if ( B ) S1
- S ⟶ if ( B ) S1 else S2
- S ⟶ while ( B ) S1

如何用控制流去写语义规则?
TODO
11.22课2
目标代码生成与基本块优化
目标代码生成器所面临的问题
-
代码生成器的输⼊:中间表示方法有很多种,比如三地址码、树、有向无环图等
-
目标程序:构造⼀个能产⽣⾼质量机器代码的代码⽣成器的难度会受到⽬标机器的指令集体系结构的极⼤影响
-
常见的指令集架构: CISC (复杂指令集计算机) vs. RISC (精简指令集计算机) vs. Stack-based (基于堆栈的结构) Machine
-
地址模式的不同:Absolute (绝对地址) Machine-language Program vs. Relocatable (可重定位) Program。使⽤绝对地址的机器语⾔程序的优点是程序可以放在内存中的某个固定位置上,并⽴即执⾏;可重定位代码的内存位置不固定
-
-
指令选择:使用什么样的指令去实现目标代码。
- IR的层次: 高层次SRC(更贴近于高级语言,不利于深度优化)、低层次BIN(更高效的代码序列)
- 指令集体系结构本身的特性
- uniformity (统⼀性) vs. special cases
- instruction speed (指令速度) vs. machine idioms (机器的特有⽤法)
- 想要达到的⽣成代码的质量: speed (运⾏速度) vs. size (⼤⼩)
-
寄存器分配:决定哪个值放在哪个寄存器里
- 寄存器分配:给定寄存器,选哪个变量进去
- 寄存器指派:给定变量,选哪个寄存器处理该变量
- 这是一个NP-complete问题,没有最优解
-
求值顺序:用什么顺序来执行计算操作,也是NP-complete问题
目标语言
基本概念
基本操作如下:
-
Load (加载运算) and Store (保存运算): LD and ST
- LD dst, addr //把位置addr上的值加载到位置dst
- ST x, r // 把寄存器r中的值保存到位置x,表示赋值x = r
-
Arithmetic (计算运算): ADD, SUB, MUL
OP dst, src1, src2 // OP所代表的运算作⽤于位置src1和src2中的值上,并把结果放到位置 dst中
-
Unconditional Jump (⽆条件跳转): BR L //控制流转向标号为L的机器指令
-
Conditional Jumps (条件跳转): BCC, e.g., BLTZ r, L。BLTZ即Branch Less Than Zero,小于0跳转。
寻址模式:

把汇编代码转换为高级语言(学计组学的):

基本块与流图
基本块:最⼤的连续(三地址)指令序列。在基本块中,只要第一条指令被执行,其余所有指令都能被执行
如何确定首指令(基本块的第一个指令):
- 中间代码IR的第一条指令
- 条件或无条件跳转的目标指令
- 跟在条件或无条件跳转后面的那条指令

在上图中按照刚才的定义,首指令分别为:
- 中间代码IR的第一条指令:1
- 条件或无条件跳转的目标指令:3、2、13
- 跟在条件或无条件跳转后面的那条指令:10、12
按照首指令对IR进行分隔就能得到基本块:

通过基本块生成控制流图CFG:CFG中每个节点代表每个基本块;每条边代表怎么跳转。

基本块的优化
优化有两种方式:
- 局部优化:在基本块内部的优化
- 全局优化:基本块之间的优化
- 为了进行优化需要绘制有向无环图DAG
- 叶子节点:初始化的变量
- 中间节点:中间变量以及做了哪些操作
- 边:表示变量和操作间有关系
例子:绘制DAG图

有哪些优化方法?
-
寻找公共子表达式:对于重复的表达式可以删掉一个。
例如上图中和是一样的(从DAG图中也能看出)
但是和并不一样,因为参数b被改过了
-
代数恒等式的使⽤:比如就是

-
强度消减:把乘法换加法,除法换乘法

-
常量合并:比如直接换成6.28;或者上面计算过的值拿下来接着用

-
数组引⽤的表示:
1
2
3
4
5
6
7
8
9//初始代码
x = a[i]
a[j] = y
z = a[i]
//是否能直接转换为以下代码?
x = a[i]
a[j] = y
z = x
//当i!=j的时候才行,如果i==j就又会重新赋值了 -
复制传播:复制传播的基本思想是在复制语句u = v之后尽可能⽤v来替代u

这样改了以后可能就不需要
x=t3这条代码了。此时我们把x=t3称为死代码,我们要对死代码进行消除。 -
代码移动:把循环中的计算移出循环

-
归纳变量:在循环中多次递变的值(就是
i++的i)看看能不能拿到循环外 -
窥孔优化:检查目标指令的滑动窗口,并将窗口内的指令替换为等价但更高效的指令序列(不能保证是全局最优)


寄存器分配和指派
全局寄存器分配:对于一些频繁使用的变量而言,会倾向于把这些变量放到寄存器中。
循环中的全局寄存器分配:

上图中B指基本块,x指变量。
例子

上图中的C(a)的use是在B2、B3中2次;hot在B1中1次。所以C(a)=4。
图着色法进行寄存器分配:
用于解决当所有寄存器都在使用时,又需求新的寄存器,就要有一个寄存器要被存到内存里去(溢出)。可以通过图着色法保证溢出的损失最小。
如何绘制寄存器冲突图:
- 节点:符号化的寄存器
- 边:一头是活跃变量,另一头是被定义的变量
- 有k个寄存器就有k种颜色
- 对图进行涂色,一个节点一种颜色,相邻节点颜色不同。
TODO:这里去找找例子看看
通过树重写来选择指令
表达式的优化代码的⽣成
TODO:11.29 课2 35:04
机器无关优化
概述
评估程序分析:
- SOUNDNESS (don’t miss any error,不会遗漏) (可靠性)
- soundness – Truth = False Positive (误报)
- Over-Approximation
- COMPLETENESS (don’t raise false alarms,不会检出错误结果) (完备性)
- Truth – completeness = False Negative (漏报)
- Under-Approximation
- 可靠性和完备性没有交集,我们做程序分析的目的是在两者中达到平衡。一般在程序安全中,漏报更加严重,即可靠性指标更加重要,我们会更着重考虑这个。
莱斯定理:程序的属性不可判定(⽐如程序是否有内存泄露、是否可以被优化等)
数据流分析
什么是数据流分析DFA
数据流:一个变量从被定义到被使用的数据流向
数据流图:用于表示数据流关系
- 节点:变量
- 有向边:定义-使用关系

数据流和控制流不同
控制流:语句执行的顺序
控制流图:节点表示一行代码或基本块;边表示执行顺序
给你一段程序,要会画控制流图:

上图中属于statement级别的CFG;可以把s2和s3合并为BB1基本块(其他的就是一行代码一个基本块)
数据流分析DFA:一种收集程序中各点可能计算值的信息的技术。作为静态分析而言,输入不同,再加上程序中的条件跳转语句,在程序中某点上的数据会不一致。
我们会关注Program Point,即每行statement之前和之后的位置
例子:以上面那个控制流函数为例画一下数据流图:
首先考虑进入while循环前的情况:这个很容易

接下来看I(BB3):注意这里是静态分析,我们要考虑所有可能的情况。那么I(BB3)中a的取值可以是来自T的1,也可以是来自F的2:

最后在while循环中,BB4的output又会作为BB3的input,即I(BB3)中的a应该是两次的并集,即1,2,3。同理这个while循环接着下去,最后I(BB3)应该是1~9。

静态分析的种类:
-
正向分析与反向分析:正向分析就是从entry到exit;反向分析就是反过来
-
可能性和必然性分析:
可能性分析:output may be true,会导致 over-approximation
必然性分析:output must be true,会导致under-approximation
下面开始讲DFA的应用
活跃(或存活)变量分析LVA
活跃变量:从程序某节点p到程序结束的某路径下,该变量的值能够被使用;否则就称该变量是死(dead)的。

LVA属于后向可能性分析。
在LVA中,指令或块通过使用变量值来使其活跃;重定义变量值来使原变量值dead。
在这里确定表达式或块的输入时,采用以下的公式:
当面临分支时,输出的确定按以下公式:

即上图中b=5这行代码的output来自于m=a+7和n=b-11这两个后继节点的input的并集。
其算法表示如下:
1 | Input: a Control Flow Graph G |
例子:对CFG图做LVA
初始下情况:

I改变后一次情况:

可用表达式分析AEA
可用表达式:对于表达式e而言,从其出现到程序点P,在任意的路径上都没有被修改过(表达式中的某个变量被重新定义过),则称e为可用表达式
AEA属于正向必然性分析。
在AEA中,用表达式在进行计算称为生成;如果任意其中的一个变量被定义了,就称为消灭。
在这里确定表达式或块的输出时,采用以下的公式:
当面临分支时,输入的确定按以下公式:
其算法表示如下:
1 | Input: a Control Flow Graph G |
例子:AEA
在进行AEA时,我们必须以BB为单位来进行分析,不能逐行代码来分析!
初次:

再来一轮没有变化。
数据流分析理论
格Lattice
定义:偏序集,且对于存在,则称P为格。
- 偏序集:对于P中的一对集合元素,它们是不可比较的
- $a\sqcup b $:上确界(最小上界)
- :下确界(最大下界)
(偏序)是一种定义在P上的二元关系,其满足自反、反对称、传递性:

如何判断一个偏序集是不是格?
如何从哈斯图判断一个偏序集是不是格?_怎么判断偏序集是否为格-CSDN博客
上界和下界的确定:

例如我这里要确定S的上下界:
-
对于P中的一个元素u,其满足对,则u为S的上界
S记为S的上确界
-
下界和下确界的定义反过来就行
-
上下确界不一定在S中,只需要在P中即可
并不是所有偏序集都有上下确界;有上下确界的偏序集是唯一的。
叉乘格:

全格:对于格P,其任意子集格S上下确界都存在,则称P为全格
几个定义:

结论:
- 任意非空有穷的格是全格,但全格不⼀定都是非空有穷的格
- 一堆全格的叉乘格也是全格
这里后面还有一些证明来不及看了,希望考试别考太多。
指针分析
基本概念
指针分析顾名思义就是针对指针的分析,其可分为指向分析和别名分析
- 指向分析:一个指针指向哪一个内存地址
- 别名分析:是否两个指针指向同一块内存地址
- 实际上两者是一个东西,指向分析完成了别名分析自然完成。
上下文敏感/不敏感:
- 上下文敏感:每次调用函数都要区分其上下文,对每次上下文都要进行分析
- 上下文不敏感:对所有的上下文只需要分析一次
例子
1 | int* id(int* x){return x;} |

流敏感/不敏感:
- 流敏感:考虑语句的执行顺序,检查每个程序点的指向关系
- 流不敏感:程序就是一组语句,从整个程序的角度检查指向关系
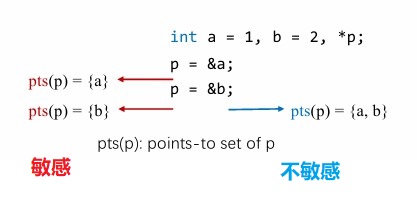
我们这里考虑的指针分析是流不敏感的可能性分析。在目标函数中,可能存在下面四种指令:
- ADDROF:
p = &a - COPY :
p = q - LOAD :
p = *q - STORE :
*p = q
Andersen风格指针分析
将指针分析视为解决集合包含问题,根据包含操作传播指向信息。

例子
1 | p = &a |

上图中的结果属于是敏感的分析。这里也可以添加从t到c的有向边,这样就是非敏感的分析。
**指针流图的画法:**仍然以上面那个为例
其算法表示如下:
1 | // Initialize the graph with ADDROF and COPY operations |
指令如下:
1 | p = &a |
-
初始化:ADDROF操作的指令作为点,COPY操作的指令作为边

-
构建Worklist:找哪个节点指向的元素非空,这里的WL是{p,q,r},从WL中依次取节点。
-
当选取的节点为p时:

-
选取节点为q:

-
选取节点为r:没有*r,也没有指向边,故没有操作
-
选取节点为a:

-
选取节点为s:

-
选取节点为t:没有*t,也没有指向边,故没有操作
-
选取节点为r:

-
选取节点为a:

-
选取节点为t:没有*t,也没有指向边,故没有操作
Andersen风格指针分析的时间复杂度在最坏情况下为,但在生产环境下一般为。
此外还有Steensgaard⻛格指针分析,这种指针分析能够将多节点合并为单节点,具备伸缩性,但是精度会变差。









